Topics -> python, telegram-bot, bots
Preview Link -> ResourceBot
Source Code Link -> GitHub
What We are going to do?
- Initialization of Resource Bot
- Extracting the icons from flaticon and blogs from csstricks
- Loading memes and quote from json file
- Making commands and providing response in real time to users
Some Important Concept
We will be using the requests-html for scraping.
But, What is requests-html?
This library intends to make parsing HTML (e.g. scraping the web) as simple and intuitive as possible.
- Full JavaScript support!
- CSS Selectors (a.k.a jQuery-style, thanks to PyQuery).
- XPath Selectors, for the faint of heart.
- Mocked user-agent (like a real web browser).
- Automatic following of redirects.
- Connection–pooling and cookie persistence.
- The Requests experience you know and love, with magical parsing abilities.
- Async Support
Requests ?
Requests is a Python HTTP library, released under the Apache License 2.0. The goal of the project is to make HTTP requests simpler and more human-friendly.
Installing Required libraries :-
pip install requests
pip install requests_html
Step 1 => Initialization of Resource Bot
First get the API from Telegram Official Page
Importing Required libraries and variables
import json
import requests
Token = "Enter your Key"
def send_messages(self, msg, chat_id):
url = f"{self.base}/sendMessage?chat_id={chat_id}&text={msg}"
if msg is not None:
requests.get(url)
Initializing the Bot class and request url with our API token
class ResourceBot():
def __init__(self):
self.token = Token
self.base = f"https://api.telegram.org/bot{self.token}"
....
Syncing the message receive
class ResourceBot():
....
def get_updates(self, offset=None):
url = f"{self.base}/getUpdates?timeout=100"
if offset:
url = url + f"&offset={offset + 1}"
r = requests.get(url)
return json.loads(r.content)
....
Sending message from our bot
class ResourceBot():
....
def send_messages(self, msg, chat_id):
url = f"{self.base}/sendMessage?chat_id={chat_id}&text={msg}"
if msg is not None:
requests.get(url)
Whole Client at Once
import json
import requests
Token = "Enter your Key"
class ResourceBot():
def __init__(self):
self.token = Token
self.base = f"https://api.telegram.org/bot{self.token}"
def get_updates(self, offset=None):
url = f"{self.base}/getUpdates?timeout=100"
if offset:
url = url + f"&offset={offset + 1}"
r = requests.get(url)
return json.loads(r.content)
def send_messages(self, msg, chat_id):
url = f"{self.base}/sendMessage?chat_id={chat_id}&text={msg}"
if msg is not None:
requests.get(url)
Step 2 => Extracting the icons from flaticon and blogs from csstricks
We will use requests-html to extract the icons from flaticon and blogs from csstricks. We will use the css selectors to locate the element.
We must have url depending on the input tag. We can frame url using our custom function.
Fetching the data from the url using Request-html
def url_to_text(url):
r = requests.get(url)
if r.status_code == 200:
html_text = r.text
return html_text
r.status_code will check the response status code. If it is valid then proceed to other part.
Parsing the Html code using HTML from requests-HTML
# It will parse the html data into structure way
def pharse_and_extract(url, name=2020):
html_text = url_to_text(url)
if html_text is None:
return ""
r_html = HTML(html=html_text)
return r_html
Getting Blogs from Css Tricks
It will find all the post using the css class. Then it will loop through all the posts and get all the required details like title and text.
def extract_from_css_tricks(res_html):
resulted_tricks = []
titles=res_html.find(".article-article h2 a")
for title in titles:
resulted_tricks.append(title.attrs['href'])
return resulted_tricks
Getting Icons from Flaticons
We will make a custom url using the input tag. Then scrape the urls from that page.
def extract_icons_url(res_html,limit=1):
icons_url = []
titles=res_html.find(".icon--holder>a>img")
for title in titles:
icons_url.append(title.attrs['data-src'])
return " \n".join(icons_url[:limit])
Step 3 => Loading memes and quote from json file
We will load the memes and quotes from file using the JSON library
with open(f'{dir_path}/memes.json', encoding="utf8") as file:
meme_data = json.loads(file.read())
with open(f'{dir_path}/quotes.json', encoding="utf8") as file:
quotes_data = json.loads(file.read())
Step 4 => Making commands and providing response in real time to users
- Make commands, so that we may know what the user want depending on the input supplied
- Framing the url when needed
- Replying using the custom formatter.
1. Initializing the commands
def make_reply(message):
reply = None
if message == '/help':
reply = "Type \n/meme to get meme \n/quote to get quote"
elif message == '/meme':
reply = random.choice(meme_data)
elif message == '/resource':
reply = "https://css-tricks.com/too-many-svgs-clogging-up-your-markup-try-use/"
elif message == '/quote':
reply = format_message(random.choice(quotes_data))
elif message.startswith('/icon'):
search_icon,*params = message.split(" ")
if len(params)>1:
flaticon_url = f"https://www.flaticon.com/search?word={params[0]}"
icons = extract_icons_url(pharse_and_extract(flaticon_url),limit=int(params[-1]))
reply = icons
return reply
We had used the custom formatter for quote command i.e format_message
def format_message(msg):
formatted_msg = ""
for i in msg:
formatted_msg += f"{i.upper()} ---> {msg[i]}\n"
return formatted_msg
How to run our Code
- Install the dependencies by following command
pip3 install -r requirements.txt - Enter your token in
main.py - Run the
server.pyto start the bot - Type `/help` to get started
- Type `/meme` to get meme.
- Type `/resource` to get recent resource. It's hardcoded in intial release.
- Type `/icon
` where `n` must be integer for how may icons you want about a particular `query`
Deployment
You can only deploy on Repl or Heroku.
Web Preview / Output
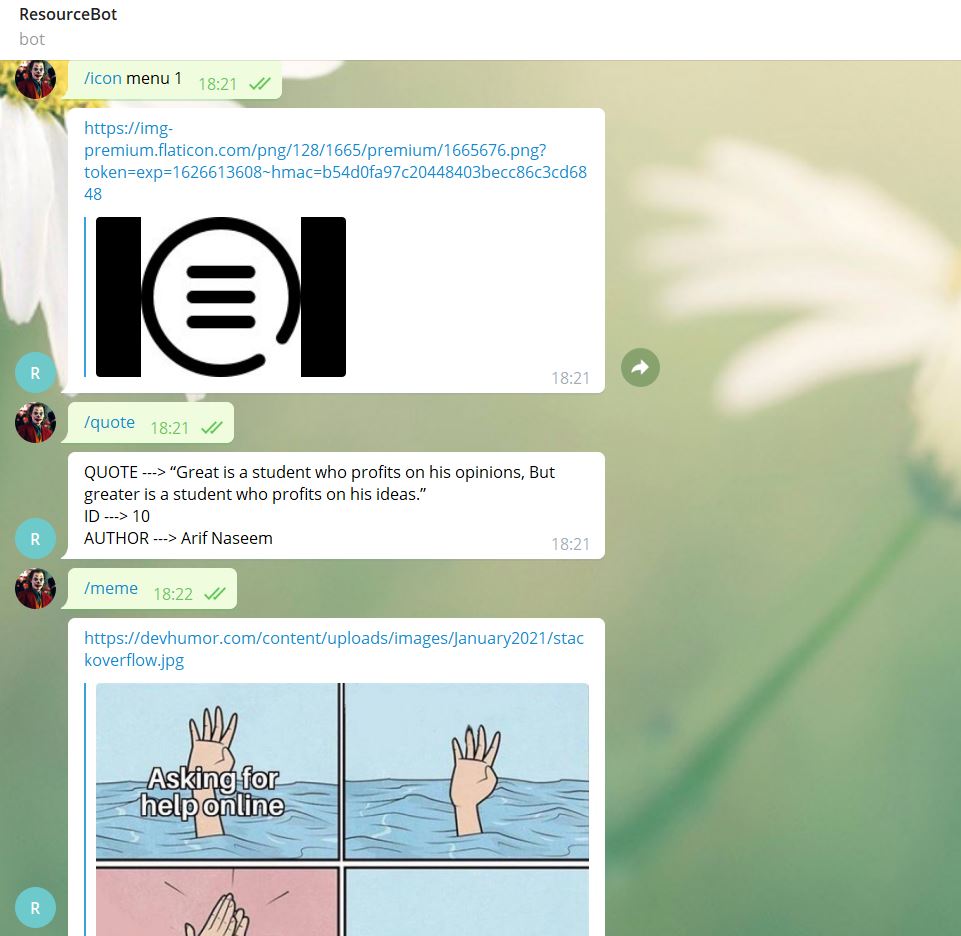 Web preview on deployment
Web preview on deployment
Placeholder text by Praveen Chaudhary · Images by Binary Beast